Hello there! The last few days, I've been at the LifeChurch.tv Central offices in Edmond, Oklahoma. As I eluded to in my last post, I was there to work specifically on the new AT&T circuits. Last fall, I talked about some network changes – including two new 100meg AT&T EaMIS burstable circuits, and a Gigabit AT&T Gigaman circuit connecting our two broadcast campuses – OKC & Central. The Gigaman circuit specifically had a nasty nasty ghost in it.
Symptom Background
So, just over a month ago, the AT&T Gigaman circuit was "live" between our Central and OKC Campuses. This was AWESOME timing becauase the Dave Ramsey Town Hall for Hope was on April 23rd at our OKC Campus. We brought the circuit live, connected our Central Cisco 6509 to the OKC Cisco 4507R, passed across our public vlan for the streaming encoders, and IP connectivity was good – or so it seemed.
During testing, there were times when the connection would just drop – for no reason – for 30-40 seconds. Then it would pick back up. We tested this for days with engineers from AT&T, Dave Ramsey's crew, Multicast Media, etc. This obviously wasn't good – when the network drop would happen, the stream would fail, and anyone watching the stream (like, for instance, 6,000 churches and millions of people) would get dead air. Not good. We eventually had to pull the plug on the "production" envionment, and isolate the Gigaman to two other Cisco 35xx switches just for the event. We did that and all was well. Funny. Must be hardware… or software… or configuration… or a ghost.
Symptom Details
Fast forward a few weeks. The Dave Ramsey event is over. We reconnect the Gigaman to the production network and begin to troubleshoot. It appears that the problem only exists when copying large files, via AFP, from Mac to XSAN. We can cause the network drop 100% when that happens. So, we go down the road to isolate Mac Servers, and XSAN devices, and… nothing changes. Crap. By this time, I've pulled in the big guns – Steve Rossen (@steve), Terry Chapman (@terrychapman), Brad Stone (@bestone), and Jim Oplot… Jim Oplat… well… JimO. We put our heads together, and I believe we actually talked about teh final solution but went different directions for some reason – probably because I don't have nearly the experience and knowledge that they do.
To give a little more peek into what happens. When data starts flowing across teh Gigaman, things look fairly normal. For instance. Consider the following "show interface" from OKC 4507 Gig3/6 (the Gigaman interface).
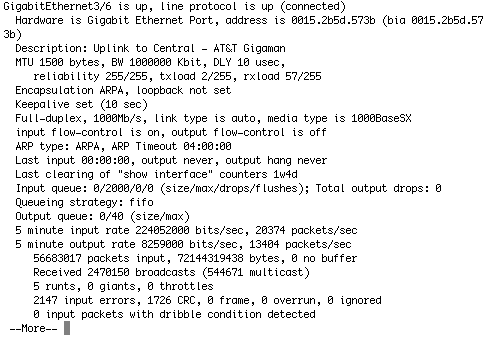
If you do the math, the interface is receiving roughly 250Mb/sec of traffic. But, notice the input and CRC errors? Those shouldn't be there.
Let's look at the OTHER side – the CEN 6509 Gig3/8 (the Gigaman interface)
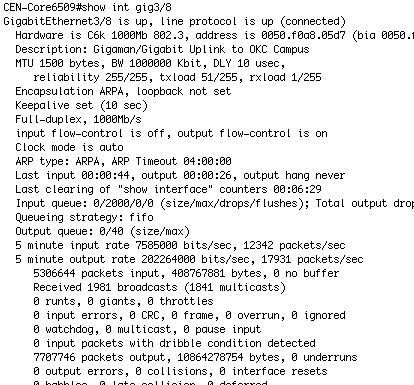
Okay, I see 200+ Mb/sec of traffic LEAVING here… and we see 250Mb/sec of traffing ENTERING at the OKC side. These are 5 minute rates. Sure. Those seem to correlate. Things are okay.
Insert network problem.
Now, look at the "show int" on the CEN 6509 Gig3/8 (the Gigaman interface on the other side)
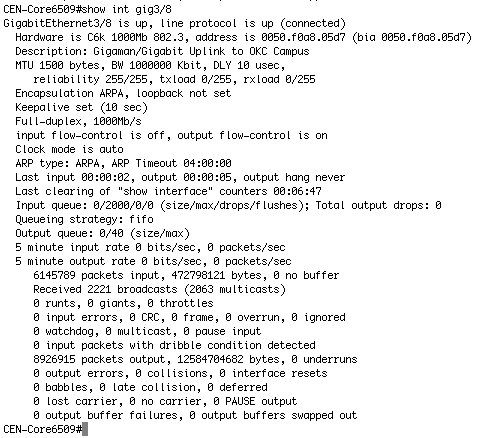
What looks odd to you? Well, this is 18 seconds later from the previous picture. You can see that because of the timing of when the "show int" counters were last reset. Now, look at the 5 minute counters. They are 0. See that? When the network problem happens, for some strange reason, it "resets" the 5 minute counters to zero. Very odd.
Troubleshooting
So, we weren't getting anywhere. I could reproduce the problem, but that doesn't really help. So, I made the decision to fly to Oklahoma to spend some dedicated time with this. Our AT&T team coordinated a ticket, a technician, and engineer and conference call so we could dive deep into the problem first thing one morning. I arrived to Oklahoma a couple days before this big meeting to work on other things. I spent one night double/triple checking physical connections, etc. and out of the corner of my eye, I saw a red light on the AT&T Metro SONET gear. I walked over to investigate and the light went off. Strange. I popped the cover on the SONET gear.

Okay, that looks normal. The OC-48 card is behind the AT&T panel. The fan lights are green. And the error lights (just above the Nortel logo) look normal.
Then it happens again.

Ahh, something is there! There **IS** as ghost! He is RIGHT THERE! What's causing that! Then the light goes back out. I decided to put this in my back burner brain cells, and focus more on the 30-40 second "downtime" and I start looking more closely into Spanning Tree. Spanning Tree is designed to help keep your network loop-free. I didn't go down the Spanning Tree route at first because we only had a single loop between OKC and Central. What I had forgotten is that Spanning Tree converges when interfaces flap (go down and then back up). Hmm. I wonder if it's something like that? Both @steve and @terrychapman mentioned that a month ago, but I didn't go down that road at the time. They are smart. I should have listened.
So, I logon the 4507R and do a "show span int gig3/6" and everything looks normal. Appropriate Roots and Fowards. Then the network glitch happens. I then do a "show span int gig3/6" and it tells me there IS no spanning tree info available. What? It was just there.
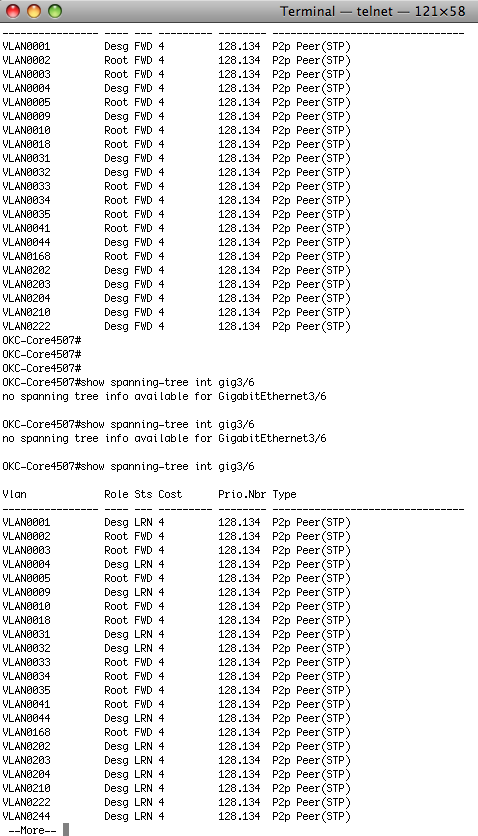
Do you see that? I did the "show span int gig3/6" a few more times, and then on the last time you see that some VLANs are in "LRN" state. Those are vlans that are reflected across the Gigaman. Something has caused them to be "blocked" and then "listened" and then "learned" and then back to normal – "forwarded." Great. Spanning Tree. The 30-40 second downtime is by DESIGN! When the problem was occuring, an interface was flapping and causing spanning tree to converge. That takes, oh, about 35 seconds.
To further prove this, I changed my configuration to be "RAPID PVST" – rapid per-vlan spanning tree. I should have had that to begin with, but I'm glad I didn't. It gave me a metric to use so when I make changes I can see if things work as expected. So, I change it. The problem occurs, and THIS time the problem is resolved in 4-5 seconds instead of 30-40 seconds. Sure enough, spanning tree was another symptom that I TOTALLY IGNORED because I didn't know enough about it. Okay. Now, why is this interface flapping – and which one is it? The PROBLEM wasn't the 30-40 second downtime. That 30-40 second downtime was like a slap in the face saying "hey stupid, there's an issue here – listen to me"
Fast forward a couple days, and during our conference call I described
the red light and sent pictures and we got the SONET engineers on the
line. Sure enough, they see errors. They don't know why. They do
notice that we are getting some light loss at the local CO – so they
schedule a fibre polish there and our Central Campus. Sure, no
problem. We get that done. Things seem "better" but not perfect.
We get a local AT&T tech (Joe) at the Central location. We get a SONET engineer on the line. Joe and the SONET guy talk for a while. The SONET engineer finally says – you're getting an error because you're sending me trash. That trash is relfected across the SONET and leading to input/CRC errors. You have a bad interface. So, I change intefaces. The problem continues. I continue to put the Gigaman on all 8 of the Fibre ports I have on the 6509 and the problem continues. Could an entire line card be bad? I have other buildings uplinked on that card with no problems. Shouldn't they have an issue?
For fun, I plug the Gigaman directly into the Supervisor of the 6509. And you know what? It worked. Perfectly. The errors went away. The SONET alarms cleared. The input/CRC errors at OKC went away. It wasn't a bad interface. It was an entire 6509 8-port fibre linecard that had a problem.
Resolution
So, we order a new card. It comes the next day. We put it in. It works.
Wow. A month later, we finally have perfectly working AT&T Gigabit MetroE (Gigaman) between our OKC and Central campuses.
The way I've explained this is like a ballon. The bad line card at the 6509 end was throwing trash across the network. It was building up pressure, like a ballon. Eventually, the pressure got too great and the inteface blew up (flapped). When the inteface flapped, spanning-tree converged and went through the BLK, LIS, LRN, FWD stages to bring things back to normal. I learned something. Hooray.
This is a long post. I know that. I put this here for a few reasons – one, remember, I blog for me. These notes help me remember what happened and I can come back to them in the future to troubleshoot. I also blog so others in similar situations can find new ways to troubleshoot. I hope it helps. Please tell me if it does.
Bro… you are my hero! Just… wow.
Great job on the troubleshooting and a great post.
Spanning tree likes to flap at you a lot, didn’t you face something similar when you started at Southeast? 😉
Did you check the card for “mad in china” sticker?
I am having a VERY similar problem, attempting to stream our services through FME, with random-ish disconnects that are driving me crazy! This week I started looking at the STP error that keeps popping up and then disappearing, I almost didn’t see it in the log before it went away. Thanks for posting this, it gives me a new lead to solving our problem as well!
I’m an AT&T central office tech who works on Gigaman’s and Cisco 6509’s, and thought I’d let you know that almost 3 years after you posted this, I found it, read it, and learned something from it. So thanks!